
起底ChatGPTAPI计费逻辑,2步教你实时测算对话成本
随着人工智能的不断发展,越来越多的企业和开发者开始使用ChatGPTAPI来提升客户服务、增强互动体验和推动创新。但是,如何高效使用ChatGPTAPI,并避免不必要的成本支出,成了许多用户关注的重点。了解ChatGPTAPI的计费逻辑,能够帮助你更精确地测算每次对话的成本,优化使用策略。

ChatGPTAPI的计费逻辑到底是如何计算的呢?在这篇文章中,我们将为你揭开这个谜团,并通过简单的两步方法,让你能够实时测算对话成本,避免被复杂的计费体系困扰。
1.ChatGPTAPI的计费模型
我们需要了解ChatGPTAPI的计费模型。ChatGPTAPI的计费基于两项核心因素:token数量和请求类型。
Token计费
ChatGPTAPI使用token(令牌)来衡量处理的文本数据量。每个token代表一段文本的基本单元,可以是一个字、一个词或一个标点符号,具体取决于文本的语言和结构。简而言之,token是API处理每次请求时的计费单位。
ChatGPTAPI将输入的文本和生成的输出文本都计算在内,这意味着每次对话的token数不仅包括用户发送的消息,还包括模型生成的回复内容。比如,你发送了100个字的输入消息,模型回复了200个字的内容,这时候总共使用了300个token。

请求类型
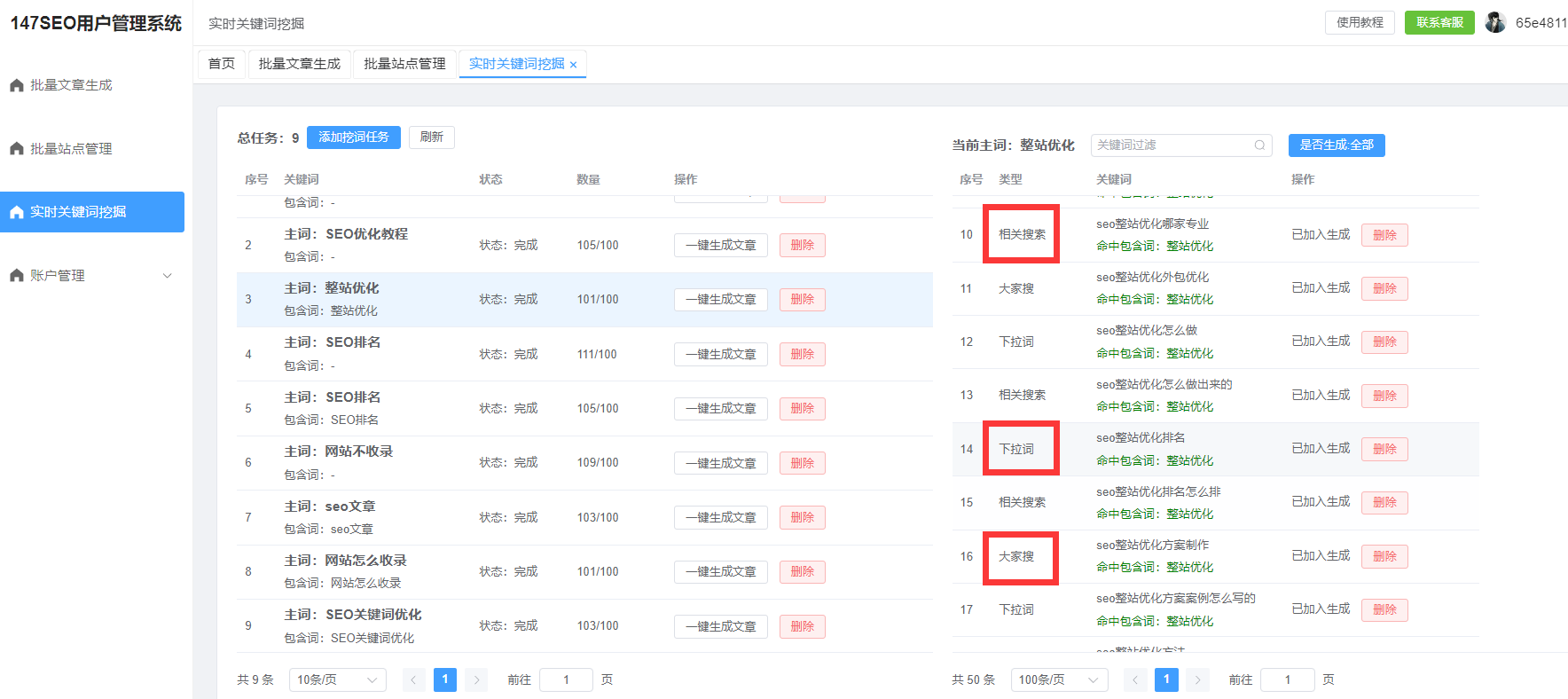
ChatGPTAPI提供了不同的接口类型,例如:Completion(完成)、Chat(对话)等。每种请求类型的计费标准有所不同。例如,Chat接口通常用于模拟多轮对话,而Completion接口则更适合单次任务的处理。不同的接口类型通常会有不同的token费用,且Chat类型可能因为包含更多上下文的对话而略微贵一些。
2.如何计算每次对话的成本?
为了帮助你更好地控制成本,了解如何根据每次对话的token数来计算费用至关重要。我们将通过两步计算方法,带你轻松搞定实时测算。
第一步:计算对话的Token数量
用户输入的Token数量:即你发送给ChatGPT的消息。这一部分可以通过计算你输入的字符数来估算。一般来说,一个中文字符大约是一个token,而一个英文单词通常对应多个token。
ChatGPT输出的Token数量:即模型生成的回复。这部分通常会比用户输入的token数多,因为模型生成的回复通常较为详细。要计算这一部分的token数,可以通过对生成的文字进行分词,估算每个词的token数量。
例如,你发送了100个字的中文消息,ChatGPT回复了200个字的内容。假设每个字对应1个token,那么总共使用的token数大约为300个。
第二步:使用API计费标准计算成本
一旦你得到了对话的token数,接下来就是计算成本。具体的费用计算方式可以参考OpenAI提供的API计费标准。以GPT-4模型为例,假设每千token的费用为0.03美元(具体费用会随使用量及不同版本而变化)。300个token的对话成本大致为:
[
300\,\text{token}\div1000\times0.03=0.009\,\text{美元}
]
这意味着一次300个token的对话,成本大约为0.009美元。
3.影响成本的其他因素
除了token数和请求类型之外,还有一些其他因素也可能影响ChatGPTAPI的成本。例如,使用高阶模型(如GPT-4)通常比使用基础模型(如GPT-3.5)贵,且不同的API版本和服务套餐可能也会有不同的价格策略。因此,在选择模型和服务时,要根据自己的实际需求进行权衡。
如果你的对话涉及较多的上下文(比如多轮对话或大量信息的处理),模型所需要处理的token数量会增加,从而导致成本上升。因此,合理地控制对话的长度和信息量,可以帮助你有效地降低开销。
在了解了ChatGPTAPI的基本计费逻辑之后,我们可以进一步如何通过优化对话结构和使用策略,来实现更加高效的成本控制。以下是一些实用的技巧,可以帮助你在使用过程中最大程度地节省开销。
1.优化对话内容,减少无效信息
在与ChatGPT进行对话时,尽量避免发送过多的无关信息。每一条消息中的文字都会计入总token数,因此减少无关内容的发送,可以有效降低使用的token量。例如,如果你仅需获取某个问题的回答,尽量将问题简洁明了地表达,而不是加入过多的背景信息。
尽量避免重复发送相同内容的请求。对于一个多轮对话,重复输入相同的信息会增加token的使用量,因此尽可能让ChatGPT记住上下文,以避免重复输入。
2.限制模型生成的内容长度
ChatGPT生成的内容越长,所消耗的token也就越多。因此,在进行对话时,可以通过限制每次输出的长度来控制成本。例如,在请求时设置最大生成token数量(如最多生成100个token),可以有效避免模型输出过长的回答,从而节省费用。
如果你使用的是API请求接口,可以在调用时通过参数控制输出内容的最大长度,这样可以防止一次对话生成过多不必要的token,进而节省开销。
3.选择适合的模型
如果你对回答的质量要求不高,可以选择一些较为基础的模型(如GPT-3或GPT-3.5),而不是高阶模型(如GPT-4)。虽然GPT-4能够提供更加精准和智能的回答,但其费用也相对较高。如果你的需求不需要那么强大的处理能力,选择更为经济的版本不仅能够减少对话成本,还能提升整体使用效率。
4.使用API的批量请求功能
对于需要处理大量对话的情况,可以使用ChatGPTAPI的批量请求功能。批量请求通常会享有一定的费用优惠,并且能够提升处理效率,从而节省更多成本。在调用API时,可以将多个请求合并为一个批量请求发送,避免每次单独请求所带来的额外开销。
5.定期检查使用报告,优化使用策略
定期查看你的API使用报告,分析每月或每周的token消耗情况,并根据数据进行优化。例如,如果某些请求的token消耗较高,可以尝试优化请求的结构或换用其他模型,降低每次对话的费用。通过数据分析和不断优化,你可以在使用ChatGPTAPI的过程中实现更加精确的成本控制。
6.使用缓存和上下文存储功能
为了避免重复计算和重复请求,可以考虑使用缓存技术,或者将对话的上下文保存在本地数据库中。这样,在用户发起新的对话时,可以快速加载之前的上下文,而无需重新计算每次的token数。通过这种方式,你可以有效地降低API请求的频率,从而节省不必要的费用。
总结
了解ChatGPTAPI的计费逻辑,并学会如何实时测算每次对话的成本,是每个使用者都应该的技能。通过优化对话内容、限制模型生成的内容长度、选择合适的模型和利用批量请求功能等策略,你可以在最大化利用ChatGPTAPI功能的控制成本,避免不必要的开销。
希望你能够更好地理解ChatGPTAPI的计费体系,并通过两步测算方法,精确计算对话成本,帮助你的项目在合理预算内取得最佳效果。


