
Python爬虫之头条采集免费方法
在如今信息化的时代,数据采集已经成为了许多行业不可或缺的一部分。对于从事内容创作、SEO优化以及市场分析的专业人士来说,一套高效、免费的数据采集方法至关重要。尤其是像头条这样的平台,其庞大的内容资源和实时更新的数据,提供了巨大的商机。很多人或许对Python爬虫有所耳闻,但如何利用Python爬虫进行高效、免费的头条内容采集,却不是每个人都清楚的。今天,我们就来详细解答这个问题,帮助你在这一领域中领先一步。
Python爬虫采集头条数据的优势
使用Python爬虫采集头条数据,能够帮助你轻松获取平台上大量的信息,包括但不限于热门文章、关键词、用户评论、新闻动态等。这对于进行市场研究、内容优化、竞争对手分析等任务,都提供了极大的便利。而且,这种方式不仅效率高,而且免费,让你无需花费额外的预算就能获得所需数据,降低了整体成本。

如何通过Python爬虫采集头条数据
1. 环境搭建与准备工作你需要安装Python及相关的爬虫库,如requests、BeautifulSoup、pandas等,这些库是进行数据抓取和分析的基础工具。你可以通过以下命令安装所需库:
pip install requests beautifulsoup4 pandas建议安装lxml作为解析器,它在解析HTML时速度较快且稳定。
2. 获取头条页面源码Python爬虫通过模拟浏览器访问头条网站,获取页面的HTML源码。你可以使用requests库来发送请求,获取页面数据。以下是一个简单的代码示例:
import requests url = 'https://www.toutiao.com' response = requests.get(url) htmlcontent = response.text此时,你已经获得了头条的HTML源码,接下来就是解析这些内容。
3. 解析网页内容通过BeautifulSoup库,你可以将HTML源码转化为可操作的结构,并从中提取所需的信息。例如,提取热门文章的标题、链接等信息:
from bs4 import BeautifulSoup soup = BeautifulSoup(htmlcontent, 'html.parser') articles = soup.findall('a', class='article-link') # 以实际页面为准 for article in articles: title = article.gettext() link = article['href'] print(f"标题:{title}, 链接:{link}") 4. 数据存储与分析采集到的数据可以存储在本地CSV文件中,或者导入数据库进行进一步分析。使用pandas库处理数据非常方便:
import pandas as pd # 存储数据 data = {'Title': titles, 'Link': links} df = pd.DataFrame(data) df.tocsv('toutiaoarticles.csv', index=False)这样,你就能轻松保存采集到的头条文章信息,便于后续分析和优化。
确保采集的合规性
在进行数据采集时,遵守头条平台的robots.txt协议至关重要。虽然Python爬虫采集数据非常方便,但一定要避免频繁请求导致平台服务器压力过大,从而影响正常访问。你可以设置合适的请求间隔,避免短时间内大量请求,造成爬虫被封禁的风险。
如何提高爬虫效率与效果
除了基本的爬取功能,你还可以使用更先进的技术来提高爬虫的效率。例如,使用代理池避免IP被封禁,使用多线程/协程加速爬虫速度,甚至结合关键词挖掘功能,定期采集与自己内容相关的热门信息。
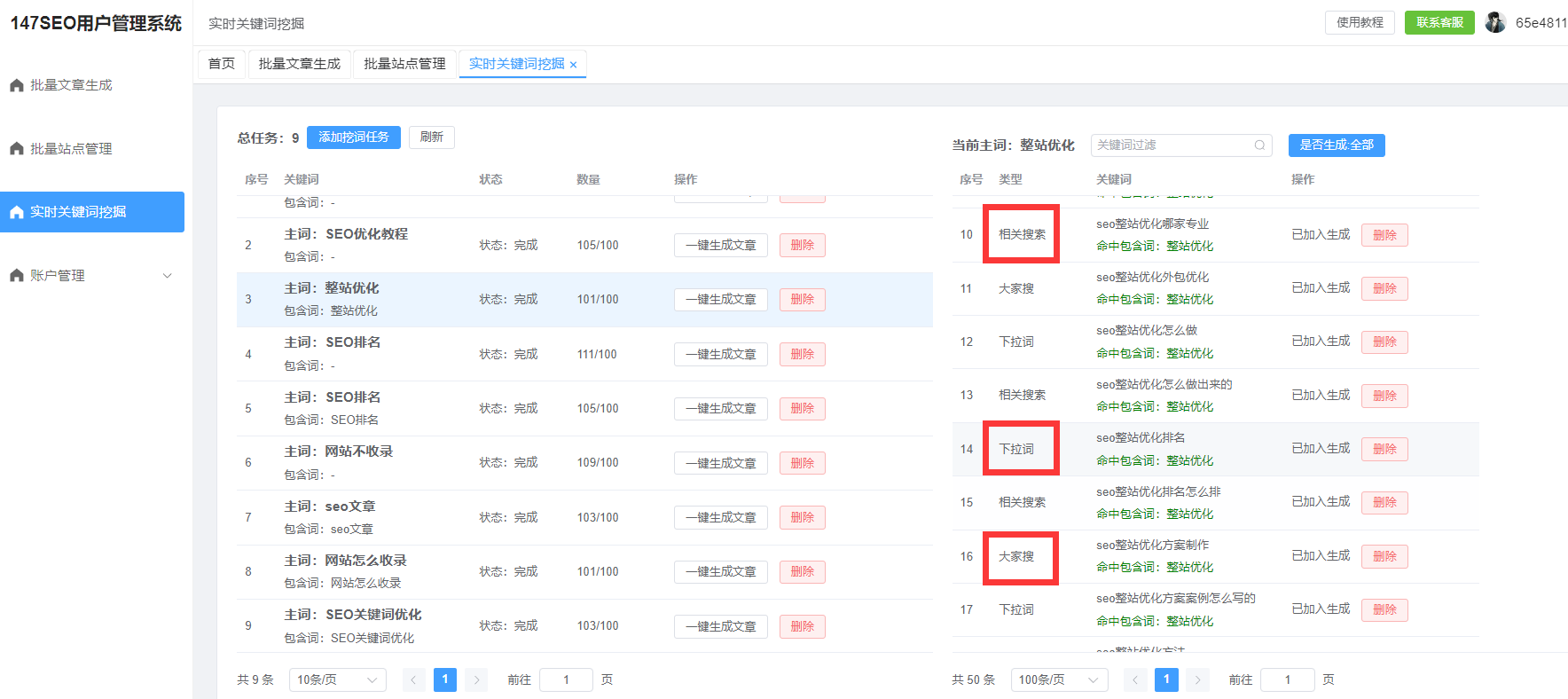
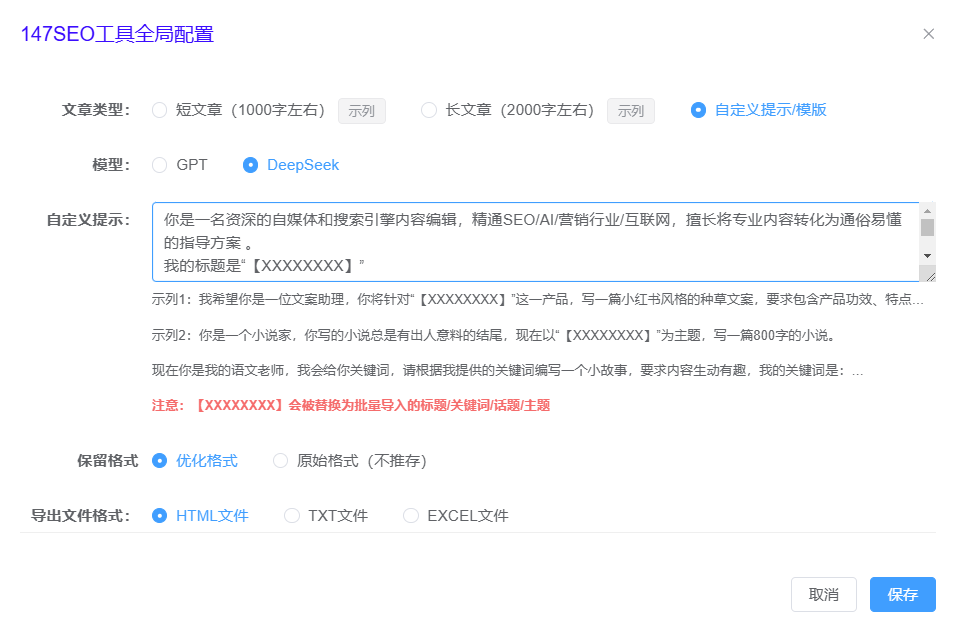
147SEO提供了多项优化功能,帮助用户在进行网站和内容优化时,提高数据抓取的质量和效率。通过147SEO的实时关键词挖掘功能,你可以第一时间获得用户最新搜索习惯的词汇,让你的内容更加贴合市场需求。而且,147SEO还支持自动发布功能,将爬取到的内容直接发布到网站,省去了手动上传的繁琐步骤。

总结
通过Python爬虫采集头条数据的过程其实并不复杂,只要你了基础的爬虫知识,按照合适的步骤进行操作,就能够轻松获得海量的数据。值得注意的是,采集数据的也要遵循平台的规定,确保数据采集合规。借助像147SEO这样的工具,能够大大提升数据采集和内容优化的效率,为你的SEO工作带来更大的助力。


