
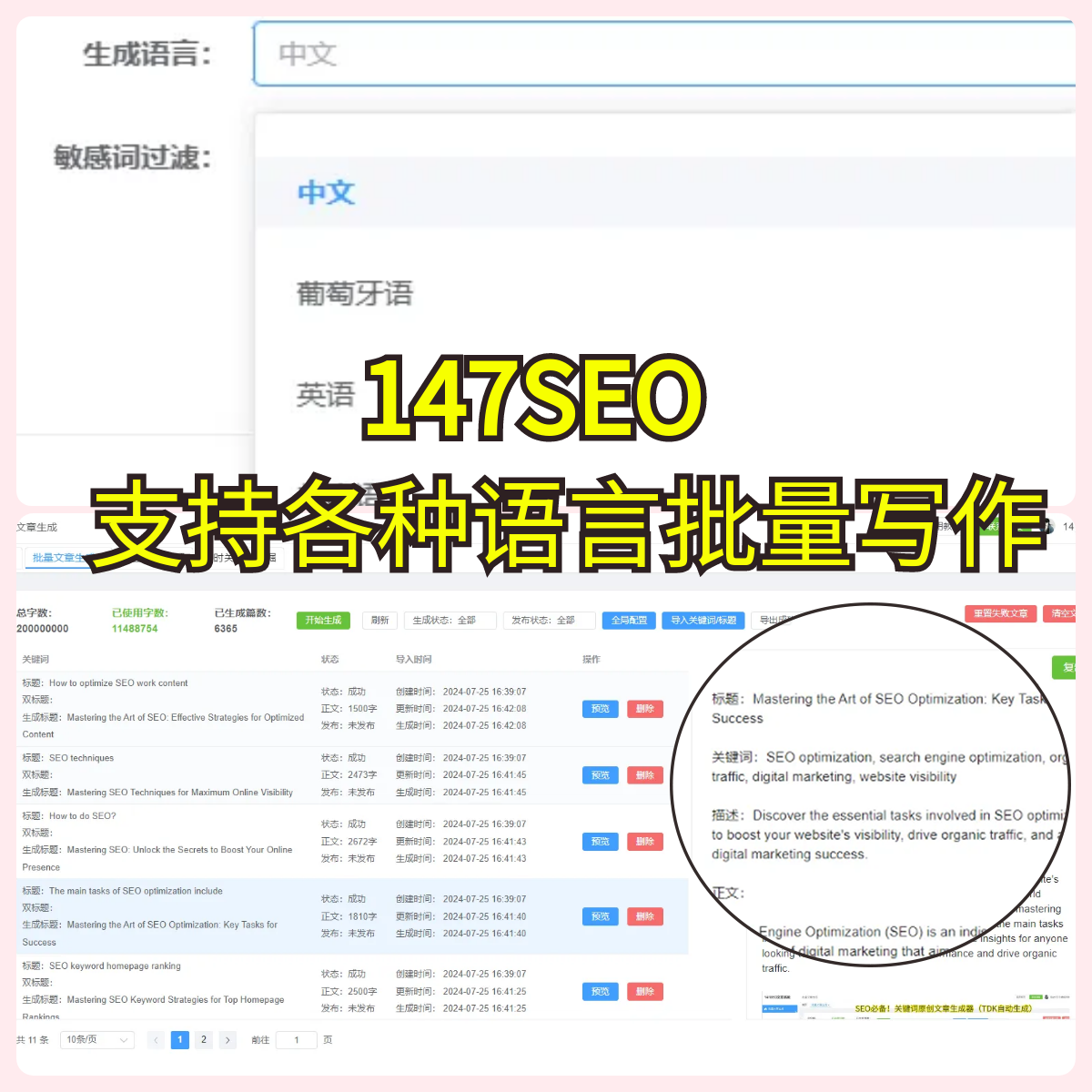
蜘蛛不来网站抓取页面怎么回事?
很多做网站优化的朋友都会遇到这样一个问题:“为什么蜘蛛不来抓取我网站的页面?”这个问题似乎没有明确的答案,尤其是当你检查过所有的基本设置,依然无法解决。是不是有一些不可见的因素影响了搜索引擎的抓取?是网站本身的问题,还是搜索引擎算法的变化?蜘蛛究竟是如何判断哪些网站值得抓取的呢?这些疑问困扰着无数网站管理员和SEO从业者。今天,我们就来一起分析一下,为什么蜘蛛不来抓取你的页面,如何避免这个问题。

一、网站结构和内容质量
如果蜘蛛不来抓取你的网站,首先需要检查的是你的网站结构。搜索引擎蜘蛛通过“爬虫程序”依照网站结构进行抓取,如果网站结构杂乱,链接不清晰,蜘蛛很可能会迷失在网站的各个页面之间,最终放弃抓取。比如,内链布局不合理或者页面之间缺乏有效的连接,都可能导致蜘蛛无法顺利抓取你的页面。

解决方法:
确保网站有清晰的层次结构,并通过内链优化来确保蜘蛛能够方便地访问到所有页面。实时关键词挖掘功能的使用,能够帮助你抓住最新的趋势,并及时调整网站内容,以提高蜘蛛的抓取频率。 可以使用一些工具,如站长AI,来检查你的站点是否有死链接、错误页面等问题,确保网站结构清晰,蜘蛛能无障碍地抓取。二、页面的加载速度和访问性能
蜘蛛抓取页面时,对于页面的加载速度非常敏感。如果你的网站加载速度过慢,蜘蛛可能在等待过程中就放弃抓取,尤其是当页面加载时间超过几秒钟时,搜索引擎可能会认为这个网站的质量较差,因此减少抓取的频次。更严重的是,过慢的加载速度还可能导致蜘蛛完全忽略你的页面。
解决方法:
优化网站的图片大小,减少冗余的脚本和插件,确保页面快速加载。 使用CDN加速,减少访问延迟,提高整体访问速度。 如果你的站点频繁更新内容,建议使用自动发布功能,将内容批量发布到多个平台,提高页面的曝光度,吸引更多蜘蛛抓取。三、robots.txt和Meta标签设置
很多时候,蜘蛛无法抓取网站的页面,可能是因为robots.txt文件或者Meta标签设置了不允许抓取的规则。尤其是一些网站管理员,可能为了防止某些敏感页面被搜索引擎抓取,错误地在全站范围内设置了禁止抓取的规则。蜘蛛抓取的过程中会遵循这些规则,如果你不小心禁止了蜘蛛抓取的权限,就会导致页面无法被搜索引擎索引。

解决方法:
仔细检查网站的robots.txt文件,确保没有禁止蜘蛛抓取的规则。 检查每个页面的Meta标签,确保没有不小心使用了“不允许抓取”的指令。 如果你担心某些页面被抓取,建议使用西瓜AI等工具,帮助你精准控制哪些页面允许抓取,哪些页面需要屏蔽。四、网站内容更新频率
蜘蛛会定期访问你的网站,但如果你的网站内容更新不够频繁,蜘蛛的抓取频率也会随之降低。这就好比一个人每天都去同一个地方,但是每次去都没有新的东西看,最后自然就不愿意再去了。网站内容的丰富度和更新频率会直接影响到蜘蛛的抓取意愿。

解决方法:
经常更新网站内容,发布新文章、博客或新闻等,增加网站的活跃度。 使用实时关键词功能,分析当前的热门话题,及时调整网站内容,吸引蜘蛛的关注。 配合批量发布工具,可以快速将更新的内容推送到多个平台,让蜘蛛有更多抓取的机会。五、外部链接和网站信任度
蜘蛛抓取网站的频率和质量,除了看内部因素,还会考虑外部的链接和网站的信任度。如果一个网站没有得到足够的外部链接支持,或者这些外部链接的质量不高,蜘蛛会认为这个网站不够权威,从而减少抓取频次。
解决方法:
通过合理的外链建设,提高网站的权重和可信度,让更多的蜘蛛访问你的页面。 在外部平台发布高质量的内容,吸引用户点击链接并访问你的网站。 使用战国SEO等工具,监控外链的质量,确保每一个外链都是有效的。结语
如果蜘蛛不来抓取网站页面,不必惊慌。通过以上方法,大家可以逐步找出问题的根源,调整策略,提升网站的抓取频率。网站的优化是一个长期而系统的工作,只有在细节上不断打磨,才能得到搜索引擎的青睐。正如爱因斯坦所说:“成功是1%的灵感加99%的汗水。”在这个过程中,正确的方法和工具,持之以恒地优化,必定能够获得更好的搜索引擎排名,迎来更多的流量和曝光。


