
蜘蛛爬取网站没有记录怎么回事?
“蜘蛛爬取网站没有记录怎么回事?”这个问题,相信很多朋友都曾遇到过。你辛辛苦苦让网站上线,设置好爬虫工具,甚至还进行了优化,期待搜索引擎蜘蛛能够顺利地爬取你的站点。几天过去了,数据依然没有任何记录!是你的爬虫设置出问题了吗?还是网站本身有啥隐形的障碍呢?别着急,今天我们就来一起这个困扰大家的问题,并寻找解决方案。

为什么爬虫没有记录?是网站设置问题还是工具问题?
大家在使用爬虫工具时,常常会有个疑问:爬虫明明已经启动,为什么没有抓取到任何数据?这种情况可能由多个因素引起,首先要排除爬虫工具本身的故障。一般情况下,爬虫程序如果运行正常,应该能顺利地抓取到网站的数据。为什么爬取结果没有记录呢?问题一:工具设置有误。每个爬虫工具的设置可能不同,有些设置了IP限制、User-Agent、反爬虫机制等参数,导致蜘蛛无法正常访问到你的网站。

如何解决呢?检查爬虫配置,确保没有错误的限制条件。比如,好资源SEO提供的爬虫功能就能够灵活地适配不同的网站环境,确保蜘蛛不受阻碍地爬取。而如果你使用的是一个自动发布工具,确保发布内容的路径和方式设置正确,才能避免爬虫漏抓。

网站本身的设置或结构问题
大家或许没有注意到,其实有些时候,网站本身的设置可能也会影响到爬虫的爬取。问题二:网站结构设计不合理或者设置了禁止爬虫访问的规则。比如,很多网站使用了robots.txt文件来告诉搜索引擎哪些页面可以爬取,哪些不能。如果网站的robots.txt文件中不小心设置了禁止爬虫访问的规则,蜘蛛就无法抓取这些页面,最终你看到的爬取记录就为空白。

怎么避免这个问题呢?检查你网站的robots.txt文件,确保没有误阻挡重要页面。你可以通过西瓜AI等工具实时监控并优化你的robots.txt文件设置,避免不必要的阻碍。
反爬虫机制:蜘蛛的“陷阱”与“解决”方案
说到爬虫,就不得不提反爬虫机制。很多网站为了保护自身内容,会设置反爬虫机制,这种机制有时非常强大,可以使得爬虫在访问时遭遇各种“陷阱”。问题三:反爬虫机制过于严格,导致爬虫无法访问网站。这种情况在大型网站或电商平台尤为常见。比如,设置了验证码、限制了IP访问频率、使用了动态渲染的网页,这些都可能让普通爬虫无法顺利抓取到网站内容。
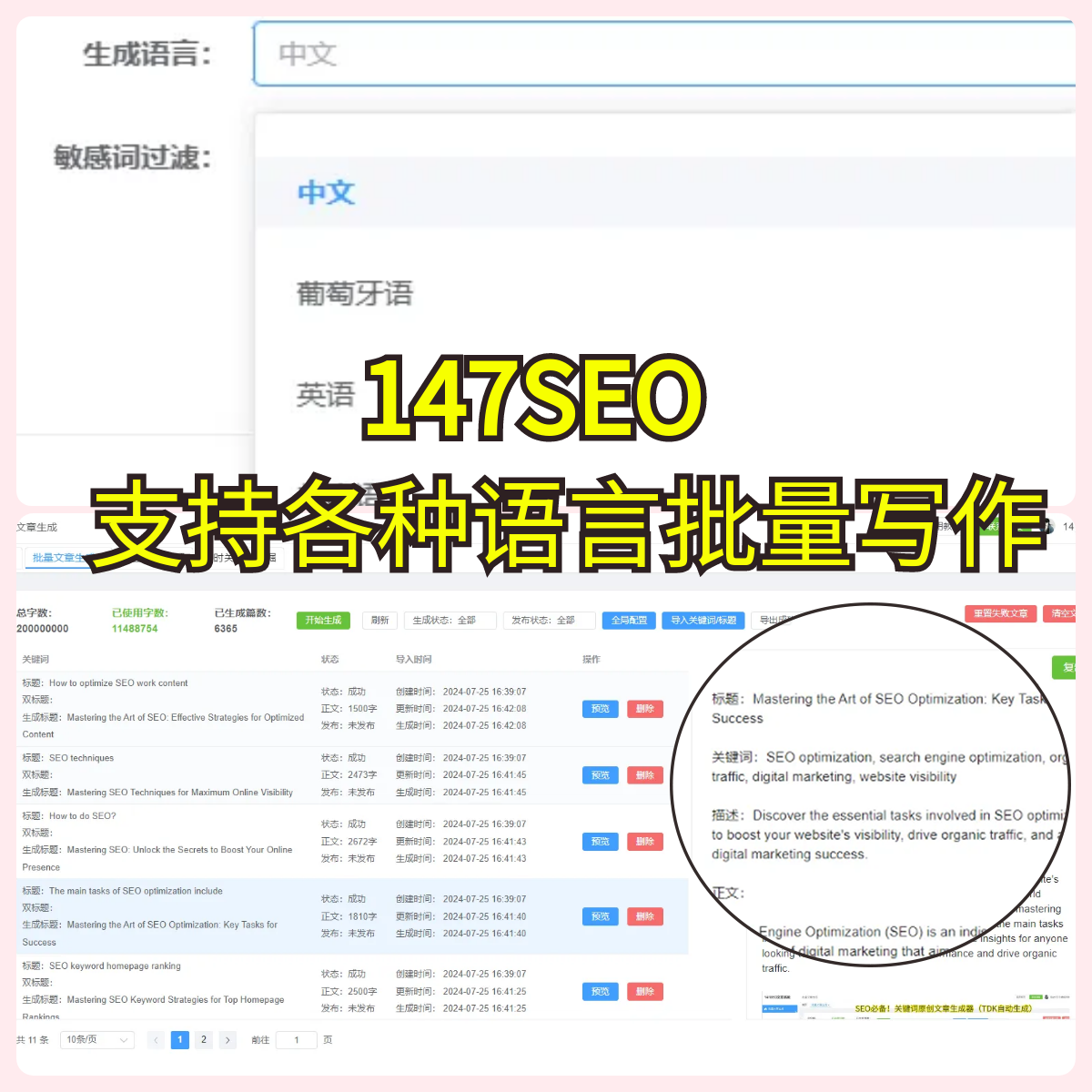
解决方案是,大家可以考虑使用一些高效的爬虫工具,例如站长AI,该工具能够突破常见的反爬虫措施,帮助爬虫稳定抓取网站数据。这样,不管你的网站采用了什么样的反爬虫策略,都能确保数据准确采集。
网站是否有流量和访问量的支持?
再来,问题四:有些网站本身流量较少,蜘蛛的访问也不频繁,导致数据没有及时爬取。这种情况通常发生在新网站或者内容较为冷门的站点上。蜘蛛爬取的优先级一般会根据网站的流量、更新频率和内容的受欢迎程度来决定。
那么如何解决呢?建议通过实时关键词功能来提升网站的曝光率,并结合批量发布功能快速增加内容的数量和质量。通过频繁更新和优化内容,提升网站的流量,让搜索引擎蜘蛛更频繁地访问你的网站。
服务器性能与访问限制
再来,问题五:服务器性能不稳定或设置了访问频率限制,这也可能导致爬虫无法正常抓取数据。如果你的服务器负载较高或者响应速度慢,爬虫就可能在访问过程中遇到超时,进而导致爬取失败。
如何解决?建议选择一款稳定的服务器,并定期监控其性能。工具如战国SEO可以帮助大家实时监控站点状态,避免因服务器性能问题造成爬取失败。
如何提高爬虫的抓取效率?
为了让爬虫更加高效地抓取数据,大家可以通过以下几种方式来提高网站的可访问性和爬取效率:
确保网站内容的更新频率高:蜘蛛喜欢频繁更新的网站,定期发布新的优质内容可以吸引蜘蛛更加频繁地访问。优化网站结构:清晰的内部链接结构能够帮助蜘蛛更好地抓取网站页面,提高抓取率。 使用高效的SEO工具:例如,好资源AI提供的实时关键词功能,可以帮助你捕捉当前热门关键词,让你的内容更加具备爬虫吸引力。结语
爬虫抓取没有记录,很多时候只是细节问题造成的。只要大家对网站进行细致的检查,避免出现配置错误或技术障碍,并且不断优化和提升站点的质量,相信爬虫的数据记录很快就会出现。就像托马斯·爱迪生所说:“成功是1%的灵感加上99%的汗水。”只要我们耐心细致地去做,问题终将迎刃而解。
每一个问题的背后,都有我们能够迎接挑战的机会。希望大家都能在实践中找到合适的工具和方法,让爬虫顺利爬取,为网站带来更多的流量和曝光。


