
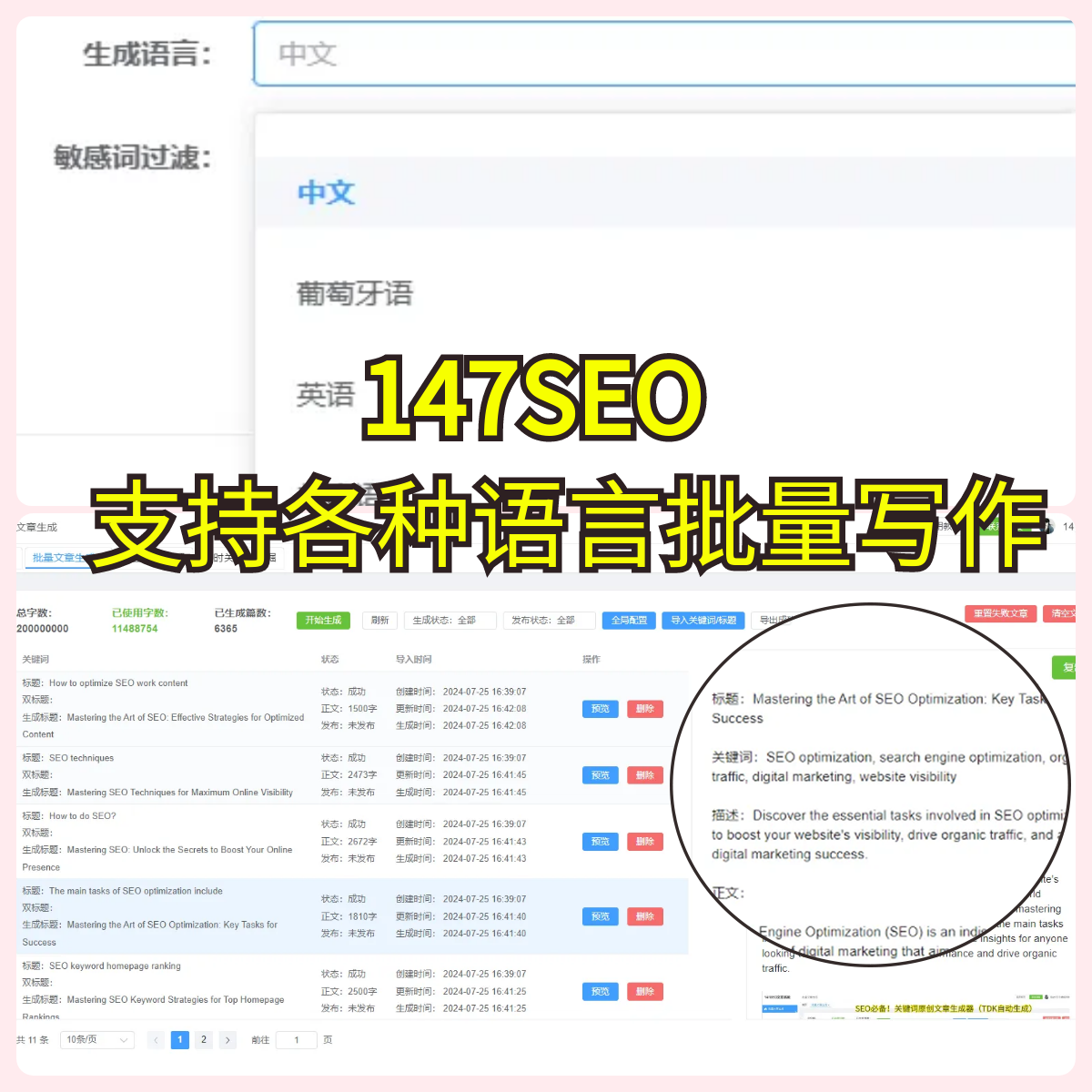
蜘蛛爬取没有记录怎么回事?
“蜘蛛爬取没有记录怎么回事?”这或许是很多站长、SEO优化人员心中的一个大难题。明明按照流程启动了爬虫,结果却发现网站的访问记录为空,甚至日志中也没有任何爬取的痕迹。这种情况让人焦虑不已,尤其是对网站的排名和流量产生了负面影响时,更是让人感到无从下手。为什么会出现蜘蛛爬取没有记录的情况?问题出在哪里?如果你也遇到过这种困扰,那么请跟随我一起分析,找出解决的办法。

一、爬虫设置问题
如果蜘蛛爬取没有记录,一定要检查爬虫的设置是否正确。很多时候,爬虫没有按预期进行爬取,可能是因为配置出错或是爬虫访问受限。
比如,爬虫的访问权限是否正确配置?一些站点会通过robots.txt文件来限制爬虫的访问。如果你没有正确设置这个文件,或者无意中屏蔽了爬虫的访问,那么自然就不会有爬取记录。网站的防火墙设置也可能是一个原因,防火墙可能会把爬虫流量当作恶意攻击流量来进行拦截,导致爬虫无法正常爬取网站内容。

解决办法:
检查robots.txt文件,确保没有错误地阻止爬虫访问。 通过查看防火墙设置,排除爬虫访问被阻挡的可能性。 如果有条件,可以尝试使用一些SEO工具,例如西瓜AI,来进行更精确的爬取记录监控,确保爬虫行为无误。二、网站访问速度过慢
另一个常见的原因是网站的加载速度太慢,导致爬虫无法在规定的时间内完成爬取。当网站响应速度缓慢时,爬虫可能会在超时之前就被迫停止抓取,进而无法记录任何数据。
特别是当爬虫访问到一些需要较长加载时间的动态页面时,如果你的服务器性能不佳,或者页面内容复杂,就可能出现这种情况。
解决办法:
优化网站加载速度,减少页面资源的加载时间。 采用一些缓存技术来提升网站的响应速度,减少服务器负担。 使用实时关键词监控功能,及时发现网站的加载瓶颈,并进行针对性优化。三、服务器问题或IP被封
很多站长可能没有意识到,服务器不稳定或者IP被封禁,也是导致蜘蛛爬取没有记录的常见原因。如果你的服务器遇到宕机、崩溃等问题,爬虫请求就会无法完成,导致爬取记录消失。某些爬虫可能由于过于频繁的访问,导致其IP地址被网站屏蔽或是被搜索引擎列入黑名单。

解决办法:
确保服务器稳定性,及时排除故障,保证爬虫的访问。 如果存在频繁访问的情况,可以尝试使用代理IP,避免因IP过度访问被封禁。 通过工具例如站长AI,对服务器的稳定性进行监测,及时发现潜在问题。四、数据记录问题
如果爬虫本身的配置没有问题,网站也没有限制爬虫的访问,为什么仍然没有记录呢?这时,问题可能出在数据记录系统上。如果你的日志系统没有正确记录爬虫访问的数据,或者日志的保存机制有误,爬取记录就会消失。
有时候,日志文件因为某种原因并未保存,或者日志文件过于庞大,导致数据丢失。这时候,即使爬虫已经成功访问了网站,记录也无法保存下来,给站长带来困扰。
解决办法:
确保日志系统能够正常记录每一次访问。 定期清理日志文件,避免日志过大导致存储问题。 利用一些第三方的SEO分析工具,如好资源SEO,来监控网站的爬取情况,确保数据记录准确无误。五、爬虫频次与调度问题
爬虫没有记录,还有可能是因为爬虫的调度频次不合理。很多站长在设置爬虫时,会选择较高的爬取频率,然而如果频次过高,爬虫可能会在短时间内对网站发起大量请求,导致访问被拒绝或者延迟,进而影响记录的生成。
解决办法:
调整爬虫的频次,确保爬虫不会过于频繁地抓取数据。 设置合理的时间间隔,避免服务器过载。 可以利用一些专业的工具,如宇宙SEO,来帮助调整和优化爬虫的调度策略,确保频次合适,避免出现爬取无记录的情况。六、内容更新与网站结构问题
网站的内容更新频率和结构也可能影响蜘蛛的爬取。若网站内容长时间没有更新,蜘蛛可能会认为网站不再活跃,降低爬取频率甚至停止爬取。网站的结构复杂或者过于庞大,爬虫的爬取路径可能会出现问题,导致某些页面没有被爬取。
解决办法:
定期更新网站内容,保持网站的活跃度。 优化网站结构,减少不必要的重定向,确保爬虫能顺利抓取每一个页面。 使用战国SEO等工具,优化网站的架构,确保爬虫能够顺利抓取到所有需要的页面。结语
爬虫爬取没有记录,看似是一个简单的问题,但实际上可能隐藏着多个潜在的原因。通过上述分析,相信大家对这个问题的原因和解决方案已经有了更加清晰的认识。在遇到类似问题时,冷静分析,逐一排查,找到根源所在,就能顺利解决。正如一句名言所说:“不怕慢,就怕站。”我们需要不断改进,不断优化,才能在互联网的竞争中稳步前行。希望这篇文章能够帮助到大家,让我们在优化的道路上不断进步!



