
ChatGPT怎么开发:智能对话系统的未来之路
随着人工智能技术的迅速发展,智能对话系统已经从科幻走向现实,成为现代科技行业中的一项重要突破。OpenAI的ChatGPT作为当前最为知名的对话生成模型之一,受到了广泛关注。它不仅仅能够与用户进行自然、流畅的对话,还能在各种领域内提供精准的回答和个性化的互动体验。ChatGPT是如何开发出来的?又是如何运作的呢?

1.ChatGPT背后的技术原理
要了解ChatGPT的开发,首先需要了解它的核心技术原理-深度学习和自然语言处理(NLP)。ChatGPT的基础架构是基于GPT(GenerativePretrainedTransformer)模型,这是一种深度神经网络结构,专门设计用于理解和生成自然语言。
GPT模型采用了Transformer架构,这使得它能够处理文本数据中的上下文信息。与传统的RNN(递归神经网络)相比,Transformer更善于捕捉远距离的依赖关系,这使得ChatGPT能够理解复杂的句子结构,生成符合语法和逻辑的自然语言。

ChatGPT采用了预训练和微调的方式进行开发。通过海量的文本数据进行预训练,模型学习语言的基本结构和知识。接着,通过针对特定任务的微调,使得模型能够在特定领域中提供更精准的回答和建议。
2.开发ChatGPT的关键步骤
开发ChatGPT的过程并非一蹴而就,而是一个持续迭代和优化的过程。通常,包括以下几个关键步骤:
数据准备与清洗
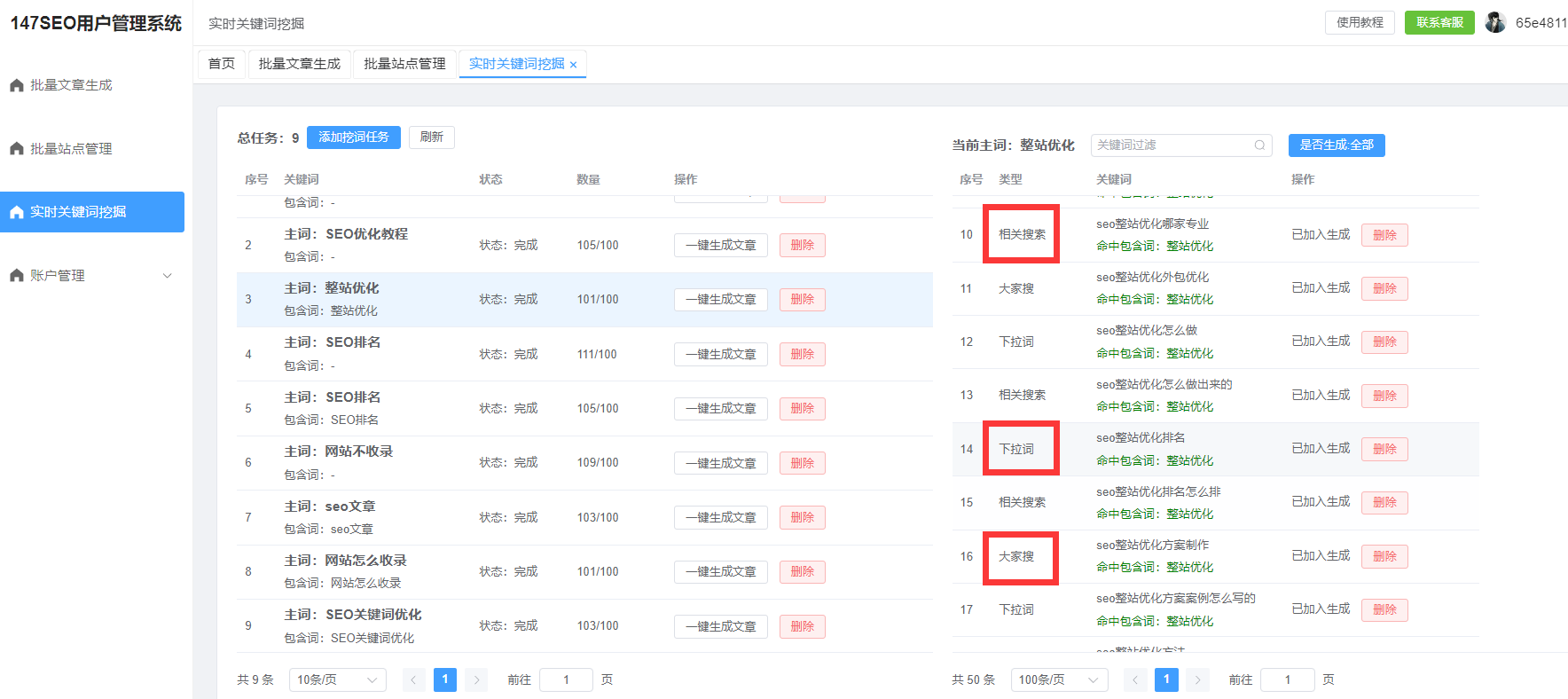
开发ChatGPT需要海量的文本数据。这些数据来自于各类网站、书籍、文章等来源,覆盖广泛的领域和主题。数据的多样性和质量直接影响到模型的表现,因此,数据的清洗和筛选至关重要。通过去除噪声数据、过滤不良信息,确保训练数据的质量,才能提高模型的准确性和鲁棒性。
模型训练
在数据准备好后,接下来就是模型训练的环节。训练过程通常需要强大的计算资源,特别是GPU或TPU等高性能硬件,以便高效地进行大量数据的处理和计算。GPT模型的训练需要花费相当长的时间,可能从数周到数月不等。训练过程中,模型会学习从输入的文本中捕捉语言的规律,从而能够生成连贯的回答。
微调与优化
虽然预训练能够让ChatGPT语言的基础知识,但为了让模型在特定任务中表现得更加优秀,还需要进行微调。例如,如果希望ChatGPT能够在医学、法律等领域提供专业的回答,就需要通过专业领域的数据进行微调,帮助模型更好地理解这些领域的术语和常识。
微调的过程通常是一个反复调整的过程,需要根据测试结果不断优化模型的参数,以确保它能够提供准确且符合预期的回答。
模型评估与反馈
训练完成后的模型需要经过大量的评估和测试。开发团队通常会设计一系列标准化的测试集,用于测试模型在不同场景下的表现。用户的反馈也是优化模型的重要途径。通过不断收集和分析用户的反馈,开发团队可以发现模型的潜在问题,并进行针对性的调整和优化。
3.ChatGPT的商业价值
开发ChatGPT的背后,不仅仅是技术层面的挑战,还有巨大的商业潜力。随着人工智能技术的普及,ChatGPT被应用于多个行业,尤其是在客户服务、在线教育、金融等领域,展示出了巨大的商业价值。
例如,在客户服务领域,ChatGPT可以替代人工客服,提供24小时不间断的服务,解决用户的常见问题,提升企业的服务效率和客户满意度。在在线教育中,ChatGPT能够为学生提供个性化的辅导,解答学习中的疑难问题,帮助学生更高效地学习。
ChatGPT还可以作为企业数字化转型的核心工具之一,帮助企业实现智能化运营,提升管理效率和决策质量。
ChatGPT作为一款先进的智能对话系统,结合了深度学习、自然语言处理等多项前沿技术,正不断推动着人工智能的发展和应用。开发ChatGPT并非易事,但随着技术的不断进步,未来将会有更多的开发者和企业投身于智能对话系统的研发当中。相信在不久的将来,ChatGPT以及类似的技术将会在各行各业中发挥更加重要的作用,带来更大的商业价值和社会影响。
随着ChatGPT的不断进步,开发者在创建智能对话系统时面临着越来越多的挑战和机遇。除了技术的复杂性外,如何让系统更好地与用户互动、提供个性化服务,也是一个至关重要的问题。以下,我们将深入开发ChatGPT时的一些技术难题和解决方案,以及如何提高系统的可用性和用户体验。
4.ChatGPT面临的技术挑战与解决方案
数据隐私与安全问题
随着ChatGPT的广泛应用,数据隐私与安全问题成为了开发者必须考虑的重要因素。许多用户在与智能对话系统互动时,可能会输入一些个人信息或者敏感数据,因此,确保用户数据的安全性和隐私性至关重要。
为了解决这一问题,开发团队需要采取加密技术,确保数据传输的安全性。还需要建立严格的数据访问控制机制,避免未经授权的人员访问用户数据。在ChatGPT的训练过程中,也需要避免使用包含敏感信息的数据,以防模型无意中泄露隐私。
模型偏见问题
另一个常见的技术挑战是模型偏见问题。由于ChatGPT的训练数据主要来源于网络文本,这些文本中可能包含各种偏见和不准确的信息。因此,模型可能会继承这些偏见,影响其输出的答案。
为了解决这个问题,开发者通常会在训练过程中加入去偏见的策略,例如对训练数据进行更严格的筛选,排除有偏见的信息,或者通过增加数据的多样性,使模型更具包容性。还可以通过增加模型输出的多样性,避免其重复生成偏见性较强的回答。
多语言支持
随着全球化进程的推进,越来越多的用户希望使用不同语言与ChatGPT进行交流。如何让ChatGPT支持多种语言,并且在每种语言中都能提供精准且自然的对话,是一个重要的技术难题。
为了应对这一挑战,开发者可以采用多语言预训练模型,将不同语言的数据输入到同一个模型中进行训练,从而让模型具备跨语言的能力。通过这种方式,ChatGPT可以在不同语言之间进行有效的转换和生成,满足全球用户的需求。
5.提高ChatGPT的用户体验
个性化推荐与定制化服务
为了让用户体验更加丰富和个性化,开发者可以通过数据分析,了解用户的兴趣和需求,进而提供定制化的服务。例如,在教育领域,ChatGPT可以根据学生的学习进度和兴趣,提供个性化的学习资源和建议。在客户服务领域,系统可以根据用户的历史记录,为其提供更符合需求的解决方案。
提升对话自然度
ChatGPT的核心优势在于它能够生成自然流畅的对话。但为了让系统的对话体验更加贴近人类,开发者需要不断优化模型的生成能力,使其能够更好地理解上下文,避免产生不连贯或机械化的回答。加入情感分析和语气调节功能,也能够使ChatGPT的对话更加具有情感色彩,提高用户的参与感和满意度。
开发一个像ChatGPT这样的智能对话系统,虽然技术复杂且充满挑战,但其巨大的商业潜力和社会价值,依然吸引着全球开发者的关注。随着技术的不断进步,未来的智能对话系统将变得更加智能、个性化,甚至能够预测用户需求、主动提供帮助。人工智能的时代已经到来,开发者们将会在这一领域迎来更多机遇,推动着技术的持续创新与进步。


