
我这个抓取是不是哦豁了
抓取数据这种事儿,呃,讲真吧,感觉一开始搞得还挺顺利的。你看,现在很多人都在说,要做好这个数据抓取,怎么说呢,其实是要有技巧的。比如你抓取网页的数据,呃,你得确保这些数据的源头啊,稳定性不差。否则的话,突然中断,或者抓取出来的内容乱七八糟,那就麻烦了。
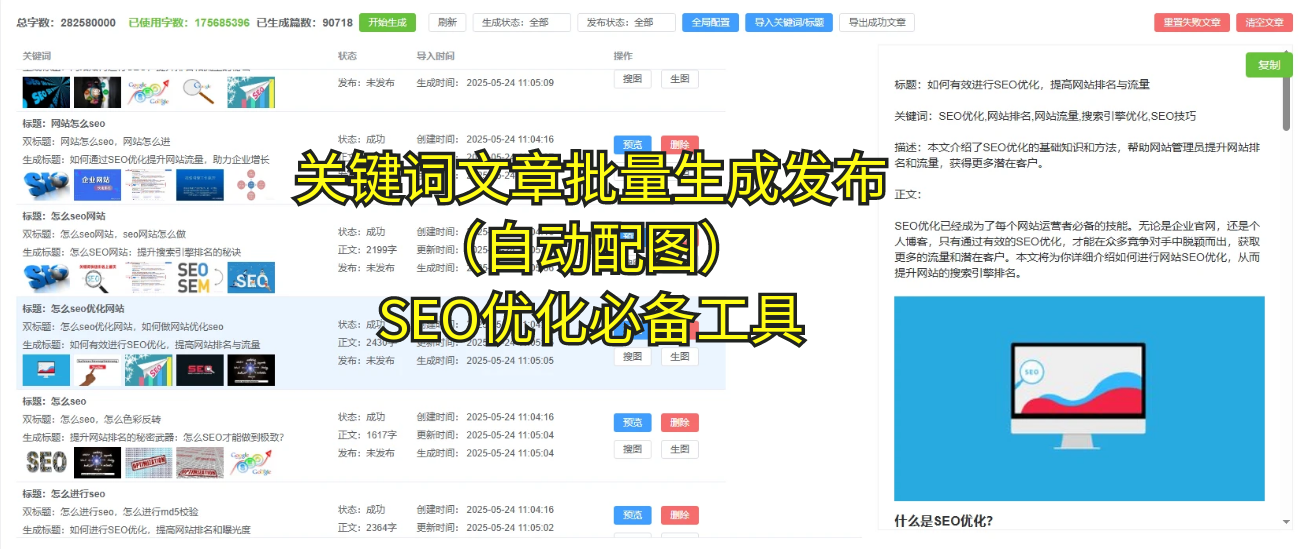
我个人感觉啊,抓取这个事情看似简单,实际上里面的坑可多了。你以为你抓取到的信息都能用?其实有时候,它的格式可能是乱码,或者就根本不符合你想要的需求。呃,像我们做这个抓取的,必须要有个规则系统,得精细到每一行数据每一个字段都能匹配到你想要的格式。否则,出来的东西呢,直接就得重做。

说到抓取,咱们说实话吧,抓取工具也有好坏,像是好资源AI这类工具,它的稳定性真的是顶呱呱。他们提供的自动更新抓取功能,几乎能实时捕捉到一些新网站的数据,这点还是挺强的。其实用起来挺省事,特别是对于一些比较专业的爬虫应用来说,呃,减轻了很多负担。
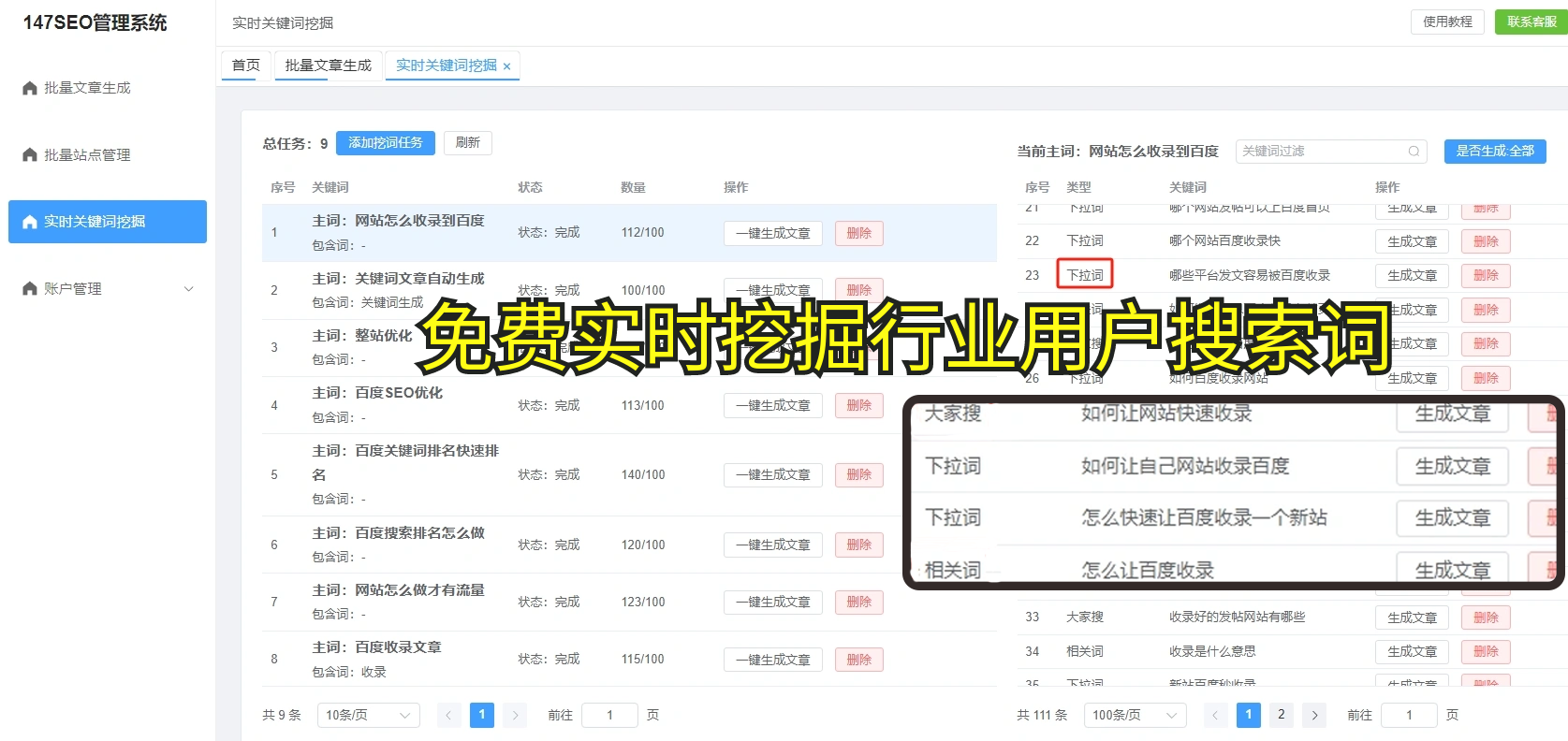
再聊聊抓取结果,大家都知道,抓取的数据吧,不仅仅是拿到就行,最重要的是,如何整理。你抓了这么多的数据,结果还得处理嘛!你想,如果没有一个清晰的架构,那这些数据,根本就不能构成什么有用的信息,不是吗?其实,最烦人的就是抓取到的数据一个个都是乱码,看得人头大。呃,所以呢,数据抓取工具有时候也得考虑一下这些情况,不然真的是浪费时间。
说到爬虫,我想起来了,前几天我还看到一款工具,叫西瓜AI,它也挺厉害的。其实吧,它不仅仅支持爬取,还能进行分析,直接就能给你筛选出有用的信息。真心觉得,像这种技术,能有效提高效率。
但话又说回来,抓取和爬虫这类技术,很多人总是觉得“哎,搞搞就好,没那么复杂”。但其实,我认为,这种想法有点误区。抓取数据的时候,尤其是涉及到大规模的爬虫,可能会涉及到很多技术性的问题,比如反爬虫机制、IP封禁问题,这些都需要提前考虑清楚的。否则你可能就会陷入“抓不到数据”的困境。
你觉得抓取能做到完美吗?说真的,我感觉很难。因为抓取出来的数据,还是得看你要用到哪个领域去。比如电商行业,它抓取出来的数据可以非常精准,但如果换到新闻资讯那块,数据的准确度就难以保证了。
有时,像一些系统的输出结果,其实吧,它不是直接能用的,还得处理。呃,所以这种事情,真的不能光靠一个工具,还是得懂一些规则,知道如何进行后期的处理。
问:如何避免抓取的数据出现乱码?
答:确保抓取时,设置好编码格式,常见的如UTF-8,避免不同编码之间的冲突。可以借助一些数据清洗工具进行后期修正。
问:如何提升爬虫的抓取效率?
答:通过并发请求、分布式爬虫等技术,可以显著提高抓取效率,减少等待时间。


